How To Remove Bias And Ambiguity In Text Annotation For Machine Learning

· Adoption of AI and NLP models is driven by their ability to process and understand human language more accurately and efficiently.
· Biases and ambiguities are hurdles to creating fair, accurate, and effective AI systems leading to consequences like discrimination, inaccurate predictions, legal, ethical, and reputational issues.
· By implementing best practices and ensuring human oversight, developers can minimize the impact of biases and ambiguities.
The use of AI and NLP models has increased significantly in recent years. This is due to advancements in deep learning, neural networks, and the availability of large amounts of data for training. We at HabileData are experiencing a substantial increase in the number of clients consulting us for accurate text annotation for their machine-learning projects.
The increasing adoption of AI and NLP models is driven by their ability to process and understand human language more accurately and efficiently, leading to improved performance and user experience in various applications. As NLP technology continues to evolve and improve, we expect that its use will keep growing across industries and applications.
Text annotation helps machines understand human language better by providing definitions and meanings. However, bias and ambiguity bring this effectiveness to a halt. Ambiguous and biased annotations result x.
Amazon’s hiring tool showed biased results. It favored male candidates due to the male-dominated resumes used during training. AI systems trained using ambiguous and non-representative data in US healthcare resulted in disparities and inequalities in healthcare.
These examples highlight why addressing bias and ambiguity, right from the text annotation process for preparing training datasets, is critical to ensure fair, accurate, and reliable outcomes.
Role of text annotation in building AI and NLP models
At HabileData, we understand how important accurate text annotation is for developing representative, successful, and unbiased AI models. Text annotation transforms unstructured textual data into structured, machine-readable formats. But, if the annotations are inaccurate, algorithms cannot understand, interpret, or make usable predictions based on the textual inputs.
Meaningful transcription and sophisticated language understanding in chatbots, sentiment analysis, and machine translation all depend on the quality of text annotation.
The risks of bias amplification in machine learning models
Bias amplification occurs when a machine learning model intensifies existing biases present in the training data, leading to unfair or discriminatory outcomes. This can have serious consequences, particularly in applications that involve decision-making or recommendations that affect people’s lives.

Bias amplification in machine learning models can lead to several risks, including:
1. Amplification of existing biases: Machine-learning models can inadvertently amplify existing biases present in the training data, leading to even more biased outcomes.
2. Negative impact on marginalized groups: Biased models can disproportionately affect marginalized groups, exacerbating existing inequalities and perpetuating discrimination.
3. Unfair decision-making: Models with amplified biases can result in unfair decision-making across various applications, such as hiring, healthcare, and other fields like law enforcement.
4. Reinforcement of stereotypes: Biased models can reinforce harmful stereotypes by generating biased content or predictions based on biased training data.
5. Ethical and legal implications: The use of biased models can raise ethical and legal concerns, as organizations may face legal consequences and reputational damage due to discriminatory outcomes.
Addressing bias amplification in machine learning models is crucial to ensure fair, accurate, and reliable outcomes.
Understanding the challenge
By implementing best practices, using advanced tools and techniques, and ensuring human oversight, developers can minimize the impact of biases on their models and create more equitable and effective AI systems. But before we get on to the rest, let’s first find out more about ambiguity and bias.
What are some common sources of bias in text annotation?
Text annotation bias can arise from annotators’ personal beliefs, cultural background, and insufficient training. Ambiguities in guidelines and source material can also introduce inconsistencies and skew results. Here are some common sources of bias in text annotation:
· Annotator’s personal beliefs or prejudices: These introduce bias in text annotation for machine learning models, leading to discrimination, inaccurate predictions, and loss of trust.
· Cultural, societal influences, and implicit biases: These biases can be introduced during the data collection, annotation, or model training processes.
· Instructive bias: These biases, which are introduced by the instructions or guidelines provided to annotators, can have several negative consequences on machine learning models.
Which are the tools used for text annotation in NLP models and constraints associated with them?
When selecting annotation tools for NLP models, some constraints, and factors to consider include cost, ease of use, and usability. Here are a few examples of annotation tools and their constraints related to these factors:
1. Label Studio: Although versatile and customizable, Label Studio may require technical expertise to set up and configure, especially for complex annotation tasks.
2. INCEpTION: It is a powerful annotation tool with many features, but it may have a steeper learning curve for new users.
3. DACCANO: DACCANO is not as widely known or used as some other annotation tools, which may limit the availability of community support and resources.
4. LightTag: LightTag is user-friendly, but it may not be as customizable as some other annotation tools, which could limit its applicability for certain annotation tasks.
5. LabelBox: LabelBox is popular, but it may require more technical expertise to set up and configure compared to some other tools.
6. TagTog: TagTog is a web-based annotation tool that offers machine learning capabilities, but it may not support all languages or have the same level of accuracy as manual annotation.
7. Prodigy: Prodigy is a modern annotation tool with many features, but it is not open-source and may have a learning curve for new users.
8. Brat: Brat is a free, browser-based annotation tool, but it requires server management and technical experience to set up and use.
When selecting an annotation tool, it’s essential to consider the specific requirements of your project and weigh the constraints of each tool against your needs in terms of cost, ease of use, and usability.
What to look at when selecting a text annotation tool?

Selecting an annotation tool for NLP is not a cakewalk. Several factors should be considered ensuring that the annotation tool meets the specific requirements of your text annotation project. Some of these factors include:
· Ease of use: The annotation tool should be user-friendly and easy to learn, especially for non-technical users or annotators who may not have prior experience with annotation tools.
· Customizability: The tool should be customizable to accommodate the specific annotation tasks and requirements of your project, such as support for different annotation types, label sets, and data formats.
· Collaboration features: If your project involves multiple annotators, the tool should support collaboration, allowing annotators to work together, share annotations, and provide feedback.
· Scalability: The tool should be able to handle large volumes of data and support efficient annotation workflows, especially for projects with tight deadlines or large datasets.
· Integration with machine learning: Some annotation tools offer built-in machine learning capabilities, which can help speed up the annotation process by providing automatic or semi-automatic annotations.
· Language support: The tool should support the languages and character sets required for your project, ensuring accurate and consistent annotations across different languages.
· Cost: Consider the cost of the annotation tool, including any licensing fees, subscription costs, or other expenses associated with using the tool.
Considering these factors might help you select a tool that meets your project requirements, however, the clients who approach us have always reported issues about comprehensive documentation and support resources like user guides, tutorials, and community forums. They do exist but don’t prove useful in troubleshooting issues.
Types of ambiguities in text annotation and how they affect the performance of NLP models.
Recognizing ambiguity in text annotation involves identifying instances where annotation guidelines and data interact, leading to multiple interpretations or unclear relationships between text and data. Addressing ambiguity is essential to improve annotation accuracy and ensure that AI and NLP models can handle diverse and complex language scenarios effectively.
Ambiguity in text annotation can be categorized into four types:
· Lexical ambiguity: When a word has multiple meanings (e.g., “bank” as a financial institution or the side of a river).


· Syntactic ambiguity: When the structure of a sentence allows for multiple interpretations (e.g., “I saw the man with the telescope”)

· Semantic ambiguity: When the meaning of a sentence is unclear due to the meanings of its individual words (e.g., “The chicken is ready to eat”).

· Pragmatic ambiguity: When the context of a sentence is insufficient to determine its meaning (e.g., “Put the apple on the table” when there are multiple apples and tables)

How can ambiguities in text annotation affect the performance of NLP models?
Ambiguities in text annotation can negatively affect the performance of NLP models by causing confusion and misinterpretation. NLP models may struggle to accurately process and understand the text, leading to errors in tasks such as sentiment analysis, machine translation, and information extraction. Addressing lexical ambiguity in text annotation is essential to improve annotation accuracy and ensure that AI and NLP models can handle diverse and complex language scenarios effectively.
Which are the potential pitfalls and real-world implications of ambiguity?
Ambiguity in text annotations can lead to several pitfalls and real-world implications on the performance of NLP models, including:

· Word ambiguity affects sentiment analysis accuracy: Ambiguous words can cause confusion in sentiment analysis tasks, leading to incorrect polarity classification.
· Ambiguity leads to misunderstanding in NLP and chatbot development: Ambiguous phrases or sentences can cause confusion and misunderstanding in NLP applications, such as chatbots, resulting in poor user experience.
· Ambiguity affects the performance of language models: Language models may struggle to accurately process and understand ambiguous text, leading to errors in tasks like machine translation and information extraction.
· Ambiguity in labeling subjective data leads to interpretation variations: When labels assigned to text data are subjective and can be interpreted in different ways, it can result in inconsistency in annotations and biased outcomes in NLP models.
· Ambiguity affects the accuracy of information extraction: Ambiguous text can cause confusion in information extraction tasks, leading to incorrect or incomplete extraction of relevant information.
Addressing ambiguity in text annotation is essential to improve annotation accuracy and ensure that AI and NLP models can handle diverse and complex language scenarios effectively.
What are the strategies for minimizing ambiguity?
The usual steps we follow at HabileData to minimize ambiguity in text annotation include:

- Clear annotation guidelines: Providing clear and detailed annotation guidelines helps annotators understand the task and the criteria for assigning labels or categories. This reduces the chances of misinterpretation and ensures more consistent and accurate annotations.
- Consistent annotator training: Training annotators consistently on the annotation task, including recognizing and resolving different types of ambiguity, ensures that they are well-equipped to handle ambiguous text and make accurate annotations.
- Iterative feedback and review: Implementing a process of iterative feedback and review allows annotators to receive guidance and corrections on their work, helping them improve their understanding of the task and minimize ambiguity in their annotations.
- Collaborative annotation process: Encouraging a collaborative annotation process, where annotators work together, share their interpretations, and discuss ambiguous cases, can help reduce ambiguity by fostering a shared understanding of the task and promoting consistent annotations.
- Domain-specific knowledge: Ensuring that annotators have domain-specific knowledge relevant to the text being annotated can help them better understand the context and meaning of the text, reducing ambiguity, and improving the accuracy of their annotations.
- Bias-awareness training for annotators: It enables them to recognize and mitigate their own biases, leading to more accurate and unbiased annotations for AI and NLP models. This ultimately improves the overall performance and fairness of the resulting AI systems.
- Fine-tuning annotation tools and parameters to prevent inadvertent biases: By adjusting the tools and parameters, annotators can better handle ambiguous or complex language scenarios, reducing the likelihood of introducing biases into the annotated data.
By implementing these strategies, we minimize ambiguity in our text annotation projects and improve the overall quality and consistency of the annotations as well as the training datasets that we deliver. It leads to better performance of AI and NLP models of our clients.
Examples of how bias fine-tuning is used to mitigate bias in the text annotation process
Bias fine-tuning is a routine approach at HabileData to mitigate ambiguity in our text annotation process. By adapting pre-trained language models to specific tasks or domains, fine-tuning helps us address and mitigate biases in text annotation. Some examples include:
- BERT models and multitask learning: Fine-tuning BERT models using multitask learning has been shown to reduce identity bias in toxicity classification tasks.
- Active learning and re-labeling: Active learning techniques have been used to improve the performance of fine-tuned Transformer models for text classification while keeping the total number of annotations low.
- End-to-end pipeline approach: Dbias, an end-to-end pipeline, detects biased words in text, masks them, and suggests less biased alternatives, ensuring fairness in news articles.
- Text preprocessing and fine-tuning: Fine-tuning models with high-quality data and preprocessing techniques, such as removing sensitive content or flagging potential hotspots for bias, can help mitigate biases in AI models.
What are some algorithmic and methodological approaches to mitigate bias in NLP models?
Here are some examples of how bias fine-tuning using algorithmic and methodological approaches are used to mitigate bias in the text annotation process:
· Data preprocessing and augmentation: Balancing datasets and augmenting data with diverse examples can help reduce biases in the training data, leading to more accurate and unbiased NLP models.
· Adversarial training: Introducing adversarial examples during training can help models become more robust against biases and improve their generalization capabilities.
· Bias detection and mitigation techniques: Detecting and mitigating biases in the text annotation process can help improve the quality and fairness of the annotated data, ultimately leading to more accurate and unbiased AI and NLP models.
· Fairness-aware learning: Incorporating fairness-aware learning techniques in the model training process can help reduce biases in the resulting AI systems, ensuring more equitable outcomes.
· Counterfactual evaluation: Evaluating models using counterfactual scenarios can help identify and address potential biases in the text annotation process, leading to more accurate and unbiased AI and NLP models.
What are some challenges in implementing algorithmic and methodological approaches to mitigate bias in NLP models?
Based on the experience of working on numerous text annotation projects, here are some challenges that our project managers face in implementing algorithmic and methodological approaches to mitigate bias in NLP models:
· The need for additional data or resources like labeled data for reweighing or adversarial examples for adversarial training.
· A lot of approaches reduce the overall performance of the model in order to achieve greater fairness, creating a potential trade-off between fairness and accuracy.
· Different stakeholders with different perspectives on what constitute a fair outcome pose its own set of challenges in defining and measuring fairness.
Monitoring and evaluating bias in text annotation
Monitoring and evaluating bias in text annotation involves assessing the consistency between annotations provided by different annotators. Using advanced tools and techniques like Fairlearn Toolkit and AI Fairness 360, conducting regular feedback sessions, and employing perturbation testing and counterfactual evaluation identifies and addresses biases in the annotation process. This leads to accurate and unbiased AI and NLP models. The monitoring and evaluation techniques include:
Techniques for monitoring and evaluating annotations
· Inter-annotator agreement: Assessing the consistency between annotations provided by different annotators can help identify potential biases in the annotation process. High inter-annotator agreement indicates that the annotators are following the guidelines and instructions consistently, while low agreement may suggest ambiguity or bias in the annotation process.
· Bias detection tools: Using advanced tools and techniques, such as the Fairlearn Toolkit and AI Fairness 360, can help detect and mitigate bias in NLP models.
· Perturbation testing: Introducing small changes to the input data and observing the impact on the model’s predictions can help detect potential biases in the model’s behavior.
How are perturbing inputs used to detect bias in NLP models?
Perturbing inputs can be used to detect bias in NLP models by examining how the model’s predictions change in response to small alterations in the input text. If the model’s predictions are significantly affected by these perturbations, it may suggest that the model is relying on biased features or patterns in the data.
· Counterfactual evaluation: Evaluating models using counterfactual scenarios can help identify and address potential biases in the text annotation process, leading to more accurate and unbiased AI and NLP models. Counterfactual generation involves creating alternative versions of the input data by changing certain features or attributes, such as gender or race. By comparing the model’s predictions on the original and counterfactual inputs, it is possible to identify potential biases in the model’s behavior.
How are counterfactuals used to detect bias in NLP models?
Counterfactuals are used to detect bias in NLP models by comparing the model’s predictions on the original and counterfactual inputs. It helps in identifying potential biases in the model’s behavior and determine whether the model is treating different groups or categories fairly.
How do counterfactuals help in identifying the root cause of bias in NLP models?
Counterfactuals help in identifying the root cause of bias in NLP models by isolating the specific features or attributes that are causing the biased behavior. By systematically altering these features in the input text and observing the impact on the model’s predictions, it is possible to determine which aspects of the data are contributing to the bias and take steps to address them.
How can counterfactuals be used in conjunction with perturbation to detect bias in NLP models?
We use counterfactuals in conjunction with perturbation to detect bias in NLP models. Our perturbation testing involves introducing small changes to the input data and observing the impact on the model’s predictions. By combining these methods, our developers gain a more complete picture of the biases present in their models and take appropriate steps to address them.
Model response comparison and its role in identifying biases
Model response comparison is a technique used to identify biases in NLP models by comparing the model’s predictions or responses to disparate inputs, like original and counterfactual versions of the text. By analyzing the differences in the model’s responses, it is possible to identify potential biases in the model’s behavior and take steps to address them. This method, in conjunction with perturbation testing, can provide a more comprehensive understanding of biases present in the model, helping developers to address and mitigate these biases effectively.
Quantifying bias using metrics
Quantifying bias in NLP models using metrics is crucial for ensuring fairness and accuracy in AI systems. By employing techniques, developers can effectively identify, measure, and address biases, leading to improved performance and more equitable outcomes in NLP models.
How can the bias introduced during the annotation process be quantified and measured in NLP models?
Bias and ambiguity in text annotation can significantly impact the performance of AI and NLP models. To quantify bias, metrics that are developed and leveraged include:
· Bias identification methods are used to detect and measure biases in NLP models by analyzing the model’s behavior across different demographic groups.
· Calibration method explores the model-level error metric across subgroups, analyzing the model’s predictions and their alignment with the actual probability of correctness.
· Counterfactual Token Fairness (CTF) gap measures the average absolute difference between the model’s prediction scores on counterfactual sentences, providing a straightforward measure of an NLP model’s bias.
· Inter-annotator agreement measures the consistency between the annotations provided by different annotators, which can help identify potential biases in the annotation process.
· Bias metrics is a quantitative measure of bias in the model’s predictions, such as disparate impact, demographic parity, or equalized odds.
· Perturbation testing analyses the sensitivity of the model’s predictions to small changes in the input data, which can help detect potential biases in the model’s behavior.
By using this metrics, developers can identify and address biases in text annotation and NLP models, leading to more accurate and unbiased AI systems.
Advanced tools and techniques for reducing bias and ambiguity
There are several modern tools and frameworks designed to reduce bias and ambiguity in AI and NLP models. Some of these include:
· Fairlearn Toolkit: An open-source Python toolkit that enables developers to assess and improve the fairness of their AI systems. It includes mitigation algorithms and metrics for model assessment.
· AI Fairness 360 (AIF360): An extensible open-source toolkit that helps users examine, report, and mitigate discrimination and bias in machine learning models throughout the AI application lifecycle. It includes over seventy metrics to quantify aspects of individual and group fairness.
· Amazon SageMaker: A cloud machine-learning platform that allows developers to create, train, and deploy machine-learning models in the cloud. It also enables developers to deploy ML models on embedded systems and edge devices.
· IBM Watson: IBM offers various AI and machine learning services, including IBM Watson, which provides a suite of tools and services for building, training, and deploying AI models.
These tools and frameworks help developers identify and address biases in text annotation and NLP models, leading to more accurate and unbiased AI systems.
How do these tools and frameworks measure the severity of bias in training data?
Here, I will provide a general overview of how these tools and frameworks typically measure the severity of bias in training data.
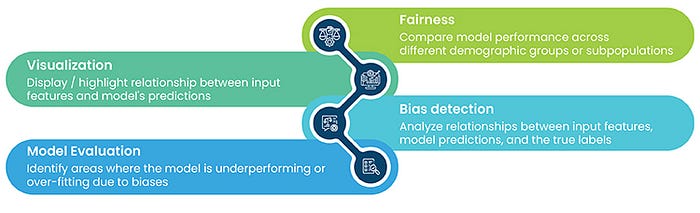
· Fairness metrics: Tools and frameworks often include a variety of fairness metrics that quantify the degree of bias in the training data. These metrics can be based on statistical measures, such as demographic parity, equal opportunity, or disparate impact, which compare the performance of the model across different demographic groups or subpopulations.
· Visualization: Some tools provide visualizations to help users understand the distribution of biases in the training data. These visualizations can include histograms, scatter plots, or heatmaps that display the relationship between different input features and the model’s predictions, highlighting potential areas of bias.
· Bias detection algorithms: Many tools and frameworks incorporate algorithms specifically designed to detect and quantify biases in the training data. These algorithms can analyze the relationships between input features, model predictions, and the true labels to identify potential sources of bias and estimate their severity.
· Model evaluation: By evaluating the model’s performance on different subsets of the training data, tools and frameworks can help users identify areas where the model may be underperforming or over-fitting due to biases in the data. This can involve comparing the model’s performance across different demographic groups or subpopulations, as well as analyzing the model’s performance on specific tasks or domains.
By using these methods, tools, and frameworks can help developers identify and measure the severity of bias in their training data, allowing them to take appropriate steps to address and mitigate these biases.
Data bias: A persistent issue
Data bias is a persistent issue in AI and NLP models because it can arise from various sources and can significantly impact the performance and fairness of these models. Reasons for these biases range from unrepresentative or incomplete training data to human biases and biased feedback loops to algorithm designs.
Importance of diverse and representative training data
Diverse and representative training data is crucial for building unbiased and accurate machine learning models. By ensuring that the training data includes a wide range of perspectives, contexts, and examples, developers can help minimize the impact of biases on the model’s predictions and improve its overall performance.
What is data selection bias in the context of large language models?
Data selection bias in the context of large language models refers to the presence of systematic errors or biases in the selection of training data, which can lead to skewed or unfair outcomes in the model’s predictions. This can occur when the training data is not representative of the diverse range of perspectives, contexts, and examples that the model is expected to handle in real-world applications.
What are some examples of data selection bias in large language models?
Examples of data selection bias in large language models include:
· Overrepresentation of certain topics, perspectives, or demographics in the training data, leading to biased predictions or recommendations
· Underrepresentation of minority groups or less common viewpoints, resulting in a lack of diversity and fairness in the model’s predictions
Are there any real-world examples of inaccurate predictions caused by data selection bias in large language models?
One real-world example of inaccurate predictions caused by data selection bias in large language models is the case of Google Translate, which has been criticized for producing gender-biased translations. This issue arises due to the overrepresentation of certain gender stereotypes in the training data, which leads the model to produce biased translations that reinforce these stereotypes.
What are reweighing and adversarial de-biasing techniques?
Reweighing and adversarial de-biasing techniques are methods for mitigating bias in machine learning models by adjusting the importance of different training examples or by training the model to be robust against adversarial examples designed to exploit biases. These techniques can help balance the distribution of the data and reduce the impact of biases on the model’s predictions.
What are some best practices for ensuring unbiased text annotation for large language models?
Some best practices for ensuring unbiased text annotation for large language models include:
· Clearly defining the annotation task and providing detailed instructions and criteria for labeling
· Providing examples of correctly annotated text to serve as a reference for annotators
· Implementing a three-stage workflow design (FIND-RESOLVE-LABEL) to minimize ambiguity
· Employing multiple annotators with diverse backgrounds and perspectives to ensure a balanced and representative set of annotations
· Implementing quality control measures, such as inter-annotator agreement and regular feedback sessions, to monitor and improve the annotation process
· Providing bias-awareness training for annotators to help them recognize and mitigate their own biases
· Using advanced tools and techniques, such as Fairlearn Toolkit, AI Fairness 360, and counterfactual generation, to detect and mitigate bias in the models
The role of human oversight in reducing bias
Human oversight plays a crucial role in reducing bias in AI and NLP models by ensuring that the annotation guidelines and instructions are clear and unbiased, monitoring the annotation process, providing feedback to annotators to improve their performance, and reviewing and validating the annotations to ensure their quality and consistency.
The significance of human intervention
By involving humans in the development and deployment of AI systems, potential biases can be identified and addressed, leading to more accurate, fair, and reliable AI systems. Human oversight also helps ensure that AI models do not perpetuate existing biases or introduce new ones, as humans can provide the necessary context and understanding to make informed decisions about the data and algorithms used in the models.
What role does human oversight play in reducing data bias in text annotation for NLP models?
Human oversight plays a crucial role in reducing data bias in text annotation for NLP models by:
· Ensuring that the annotation guidelines and instructions are clear and unbiased
· Monitoring the annotation process and providing feedback to annotators to improve their performance and minimize biases
· Reviewing and validating the annotations to ensure their quality and consistency
· Identifying and addressing potential biases in the training data and the models themselves
What are some challenges in implementing human oversight to reduce data bias in text annotation for NLP models?
Some challenges in implementing human oversight to reduce data bias in text annotation for NLP models include:
· The time and effort required to monitor and review the annotation process
· The potential for human reviewers to introduce their own biases into the process
· The difficulty of identifying and addressing subtle or implicit biases in the data and the models
Future outlook
The future outlook of text annotation for NLP models is promising, as the field of NLP is evolving, and simultaneously annotation tools are getting more sophisticated and powerful. The demand for textual data is increasing across various industries, and high-quality annotations are vital for building accurate and robust models.
As NLP applications, such as chatbots, virtual assistants, and sentiment analysis, become more advanced, the importance of text annotation will continue to grow. The development of new tools and frameworks will further help in identifying and addressing biases in-text annotation, leading to more accurate and unbiased AI systems.
The evolving landscape of annotation
The landscape of text annotation is continuously evolving, with new tools, techniques, and best practices emerging to address the challenges of bias and ambiguity. As AI and NLP models become increasingly sophisticated and integrated into various applications, the importance of high-quality, unbiased annotations will continue to grow.
Advancements in tools for bias and ambiguity mitigation
Advancements in tools for bias and ambiguity mitigation, such as the Fairlearn Toolkit, AI Fairness 360, and counterfactual generation, help developers better understand and address biases in their models. As these tools continue to improve and new techniques are developed, the ability to detect and mitigate bias in NLP models will become more efficient and effective.
Conclusion
Addressing bias and ambiguity in text annotations is essential for building accurate, fair, and reliable AI and NLP models. By implementing best practices, using advanced tools and techniques, and ensuring human oversight, developers can minimize the impact of biases and ambiguities on their models and create more equitable and effective AI systems.
